I trained a 20-million-parameter world model on two hours of raw DOOM (1993) gameplay. It can run on laptops and smartphones. Everything is open source: the code, the model weights, and the dataset are all publicly available.
I chose DOOM because it is a cult game with simple visuals, discrete actions, and a lot of raw gameplay footage available online. The rest of this article walks through the approach and shares some results.11 For the full theory, you should read the LeWorldModel paper.
Introduction to world models
Deep neural networks are surprisingly good at learning non-linear functions, and world modeling happens to be one of them.
At a high level, a world model is a function that maps previous states and actions to the next state. Everything happens at the vector level, inside embeddings. This function is what our predictor will learn.
States are encoded by a vision transformer (ViT), and actions are encoded by a multi-layer perceptron (MLP).
This means that world modeling can be defined as follows:
where is the world dynamics function, is the vision encoder, is the state, is the action, is the RGB image, is the timestep, and is the model’s dimension.
In practice, the model takes a window of past states and actions to predict the next state, which leads to the following loss function:22 In this example, I use the L1 loss function, but you can use others such as MSE.
Here, is the maximum context window and denotes the model weights. The term shortens the window at the beginning of an episode, when fewer than previous timesteps exist.
With a sufficiently large and diverse dataset, a neural network can learn the world described by it, and generalize to unseen data from the same world.
One important detail is that every state and action vector is encoded by the world model itself. Without proper regularization, the model will instantly collapse, producing a single constant vector for every input. To prevent this, I use the SIGReg regularizer from LeJEPA in my loss:
where is a hyperparameter.
This regularizer forces the world-model’s embeddings to match the distribution of an isotropic Gaussian target. Thanks to this, the world-model is prevented from collapsing, that is, from taking a shortcut and learning a constant.33 For more details about SIGReg, read the LeJEPA paper, or Appendix A of LeWorldModel for a gentler introduction.
The rollout loss is making the world model predict while giving its previous predictions as context. I introduced it because the predictor was collapsing in autoregressive setups. This was first introduced in the V-JEPA 2 paper to fine-tune their model for robotics.
However, with the definition above, we only get a latent world model. In other words, the model can only “think” inside its own vector space, and it does not produce the kind of visual results you get out of the box from pixel-based world models.
Learning from unlabeled gameplay
Training a world model requires an action vector for every frame, but raw gameplay videos do not contain those action vectors.
To get around this, I trained my own Inverse Dynamics Model (IDM),44 The IDM weights are publicly available. following the approach from OpenAI’s 2022 paper, “Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos”.
The idea is fairly simple. First, you collect a small labeled dataset by recording gameplay along with the actions taken by human players. Then, you train an IDM to infer what actions happened between frames from the surrounding video context. Finally, you run it over the rest of your raw, unlabeled footage.
For the IDM dataset,55 The IDM pretraining dataset is publicly available. I recorded myself playing DOOM through VizDOOM, a library that exposes DOOM as a reinforcement learning environment. This gave me the ground-truth action label for each frame, and it only took 30 minutes to record.
Decoding the latent world
The decoder is a vision-transformer with a “reverse” convolutional network that generates frames by using Pixel Shuffling and upscaling. It uses AdaLN to condition the encoder’s patches with the [CLS] token from the predictor.
As I mentioned earlier, latent-based world models are optimized to produce highly abstract embeddings for prediction and planning, not for generating pixel images. This makes building a high-quality decoder difficult.
The core tension is that giving the decoder too much influence over the world model causes it to collapse toward a constant output, and giving it none results in noisy images. I went through several attempts to find the right balance.
Training the decoder jointly with the world model collapsed immediately:
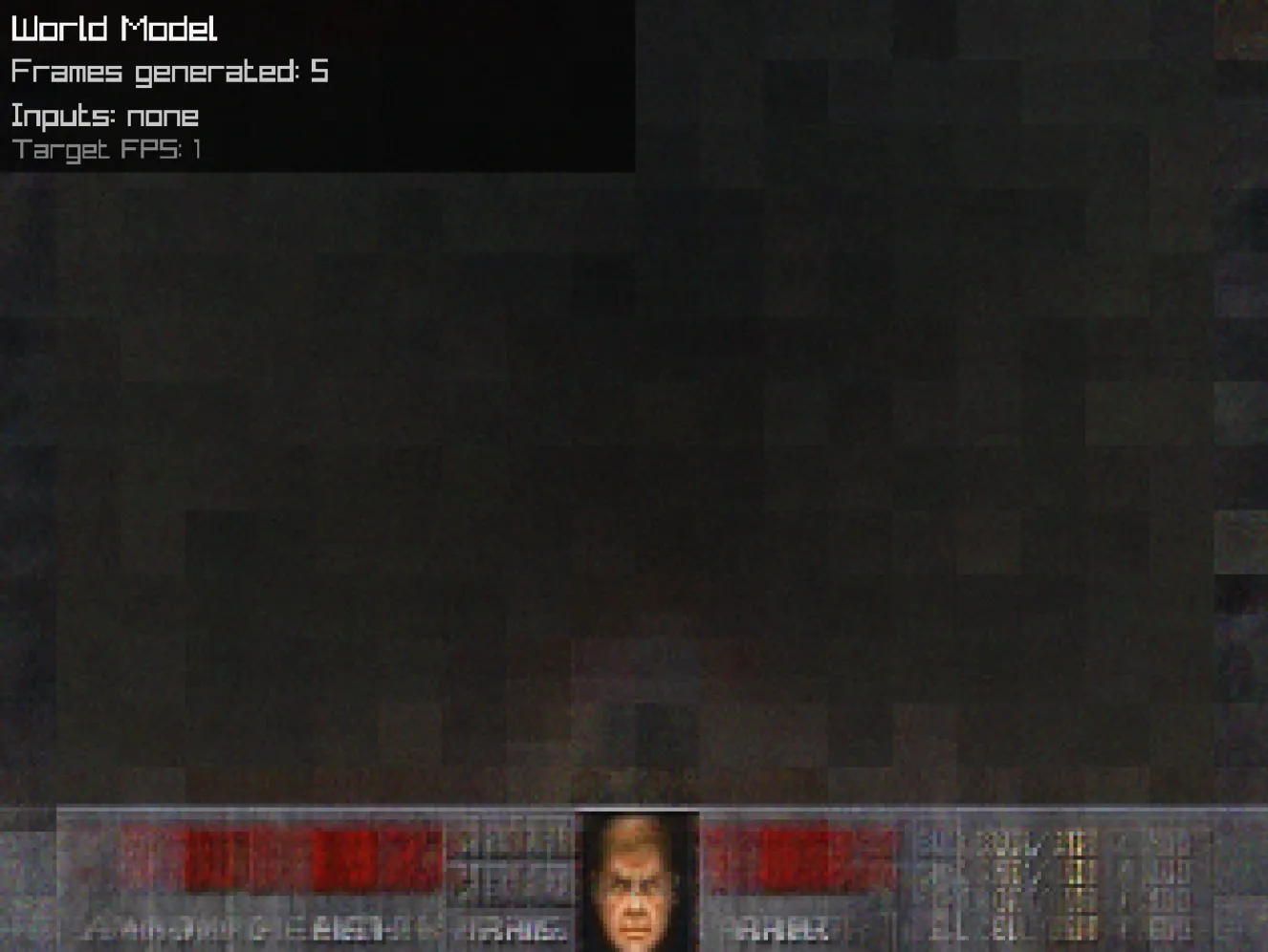
Training it on a frozen world model with only the L1 loss gave noisy but interactive results:66
This one was mind-blowing, because we can see logical updates of the output. When I use the action ATTACK, we can see a zone of the image lighting up, symbolizing a gun firing.
I also tried looping the decoder and the world model to “dream”: give the encoder a generated frame from the decoder, pass its [CLS] token to the predictor, and generate the next frame, all in a loop. The encoder fell into an out-of-distribution state when receiving decoder outputs. I still think this process has a lot of value for synthetic video generation.
The paper on “Representation Autoencoders (RAE)”77 Thanks to Tommie Kerssies for sharing this paper! showed a better path: by training a decoder on top of a frozen vision-encoder, it is possible to generate high-quality images without training a full autoencoder. The predictor generates embeddings in the same space as the vision-encoder, so this method applies directly.
I followed their approach with this loss:
where is a hyperparameter, is the generated frame, and is the true frame at timestep .
The Learned Perceptual Image Patch Similarity (LPIPS) loss uses an AlexNet model to measure the semantic similarities between two images at the feature level.
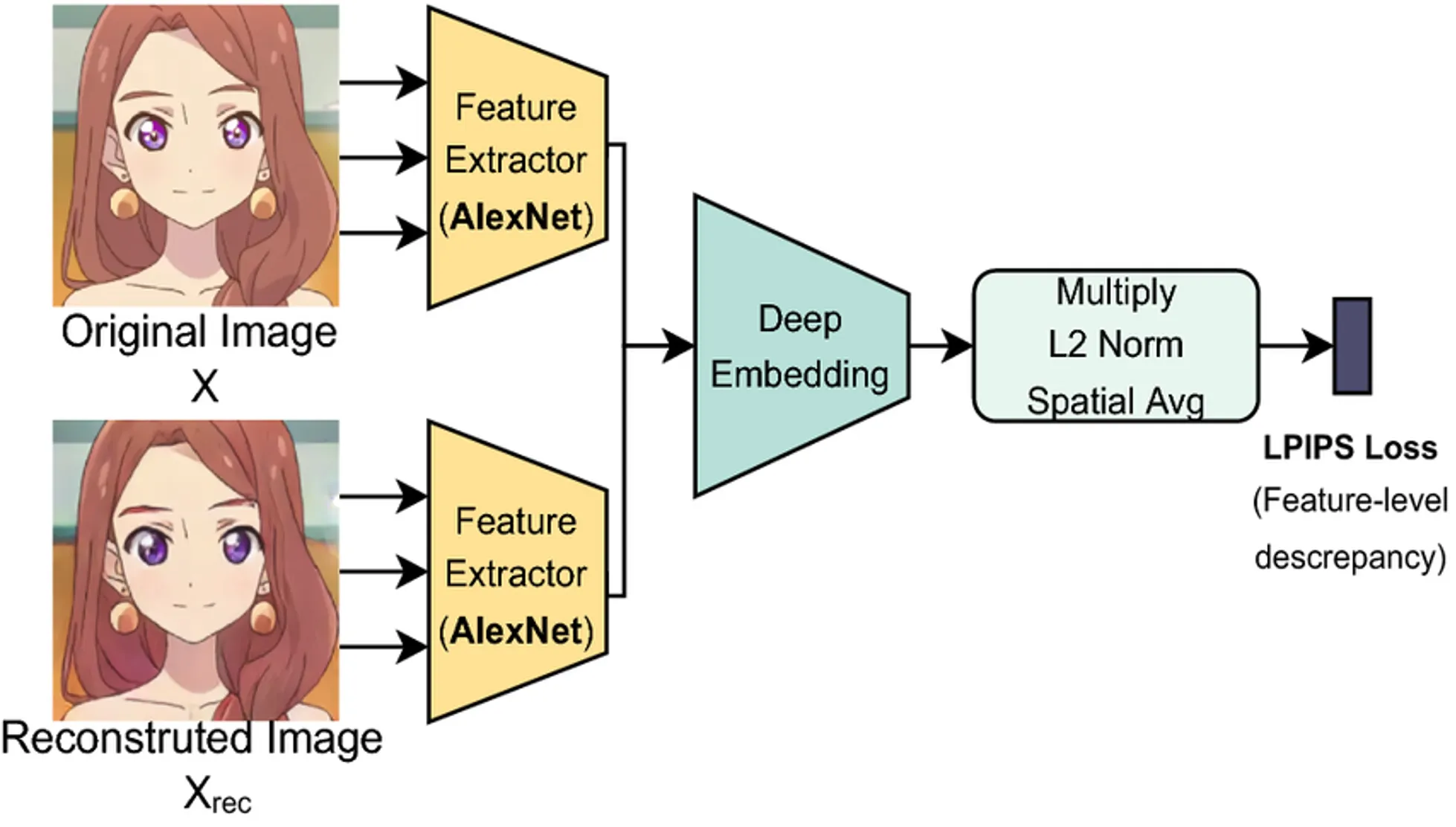
The [CLS] token of the predictor is not enough to generate good-looking frames, so I also feed every patch from the encoder to the decoder.
In this training framework the [CLS] token can be seen as a delta token.88
I was inspired by the paper “A Frame is Worth One Token”.

Here is the result of this training recipe:

The decoder is limited in low-level details. It also completely ignored the [CLS] from the predictor, making it impossible to see the dynamics of the game. I tried adding a GAN to the loss to fix this:
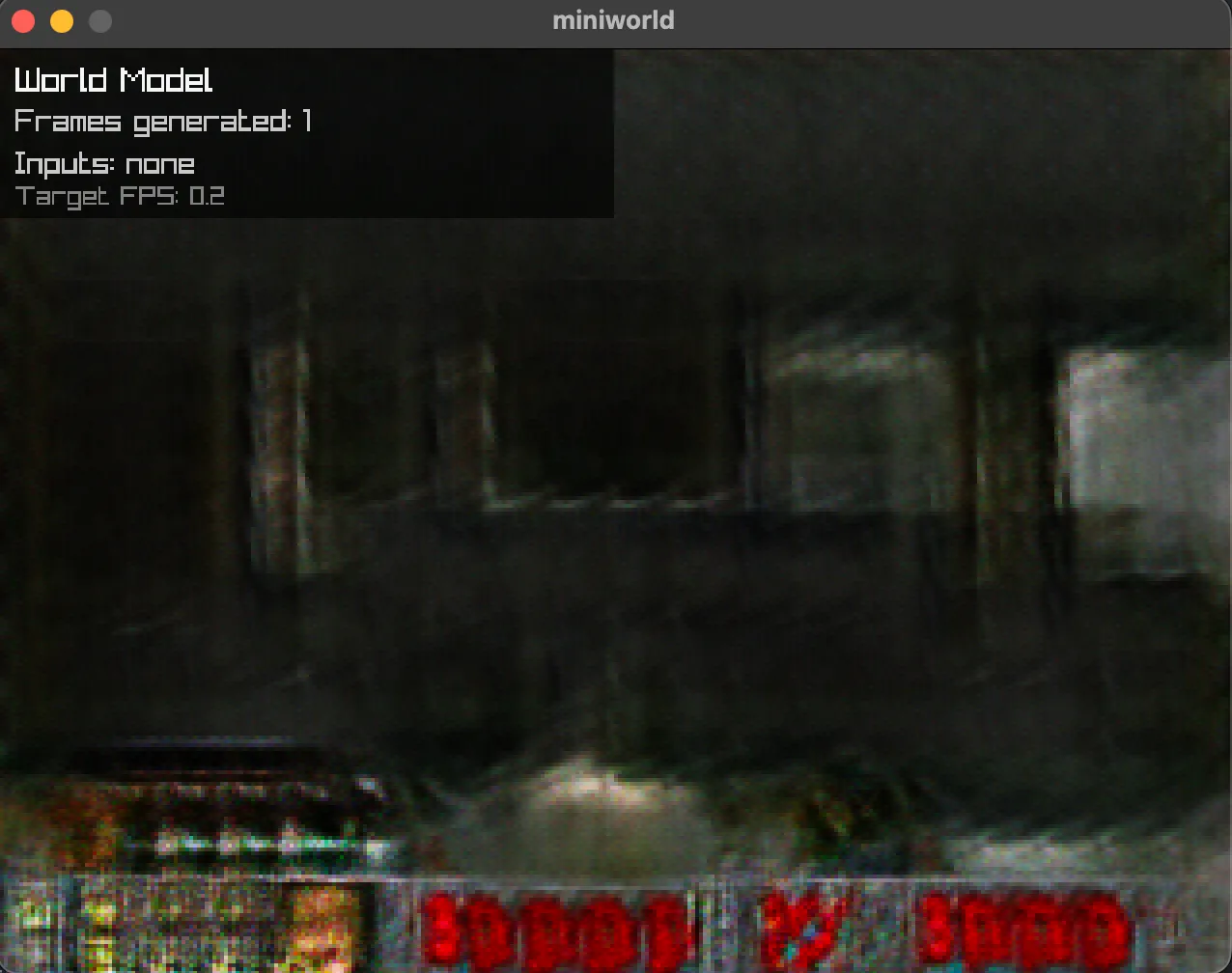
I believe using the GAN was the right approach but sadly the training was way too unstable: the discriminator was too strong and the decoder was too weak.
Letting the model play DOOM
You can use a world model for decision-making without any additional training.
This is called gradient-based planning.99 If you want more details, you should read this paper. Instead of training a separate policy network,1010 Gradient-based planning and policy learning are not mutually exclusive. You can also train a policy on top of this system to improve its capabilities, and the combination works well. The policy takes the current state and produces initial action proposals, which gradient descent then refines, speeding up planning. you directly optimize an action sequence with a gradient-based optimizer (Adam, SGD, and so on), until the predicted future state converges toward a target.
However, gradient-based planning still requires a reward model to guide the planner, and the whole process is memory-hungry. My MacBook Air M1 cannot evaluate thousands of candidates.
I still tried, and here is an attempt at gradient-based planning on my laptop:
Following this failure I trained an Action Policy instead, a small transformer that takes the [CLS] token from the world model and predicts the next action to take.
As you can see, this version is not really good at playing DOOM. It’s not really good in an autoregressive setup, although it can predict the next action in the dataset at ~ accuracy.
You can do much more than this with an action policy. You can train it with Reinforcement Learning entirely inside the world model, since the policy only operates in latent space. This approach was explored by a team at Google DeepMind with Dreamer 4. I believe this is the best approach for this type of policy for world models.
If you want to try it yourself, you can clone the repository, install the pre-trained weights, and run the autoplay.py script. It should run in real-time on most devices. But before doing so, you should buy the game and use the official WAD file for the model to perform at its best. You can try with Freedoom or other mods if you don’t want to buy the game, although the results will likely be noticeably worse than with the original DOOM assets.
Limitations and final thoughts
The demonstrations I’ve shared in this article are not great in my opinion, they can be way better. The decoder and the action policy are both limited by their size (less than 10 million parameters each), by the fact that they are under-trained and also because the training recipes I was following were not perfect.
Sadly, I’m stopping here on this long project. It was an incredible experience, and I learned a lot about deep learning and world models.
I believe world models are the next major lever for pushing deep learning forward. They are data-efficient, they can produce large amounts of synthetic data, and they can be deployed in almost any environment. Anyone can build a domain-specific action decoder, whether for desktop GUIs, robotics, or video games.
Pairing this with efficient optimizers such as Muon or Aurora should push things even further.
I hope I’ve inspired some people to dive into latent world models. I genuinely believe they are the future of AI.
Footnotes
-
For the full theory, you should read the LeWorldModel paper. ↩
-
In this example, I use the L1 loss function, but you can use others such as MSE. ↩
-
For more details about SIGReg, read the LeJEPA paper, or Appendix A of LeWorldModel for a gentler introduction. ↩
-
The IDM weights are publicly available. ↩
-
The IDM pretraining dataset is publicly available. ↩
-
This one was mind-blowing, because we can see logical updates of the output. When I use the action
ATTACK, we can see a zone of the image lighting up, symbolizing a gun firing. ↩ -
Thanks to Tommie Kerssies for sharing this paper! ↩
-
I was inspired by the paper “A Frame is Worth One Token”. ↩
-
If you want more details, you should read this paper. ↩
-
Gradient-based planning and policy learning are not mutually exclusive. You can also train a policy on top of this system to improve its capabilities, and the combination works well. The policy takes the current state and produces initial action proposals, which gradient descent then refines, speeding up planning. ↩